3 Overview of RNA Sequencing
3.1 A Refresher
The nucleus of almost every cell contains genetic material (Deoxyribonucleic acid / DNA). DNA encodes the blueprints necessary for the functioning and development of living organisms - the proteins that make up our bodies and regulate its functioning.
To produce a protein, a copy of the gene encoding for it is made with RNA (Ribonucleic Acid).
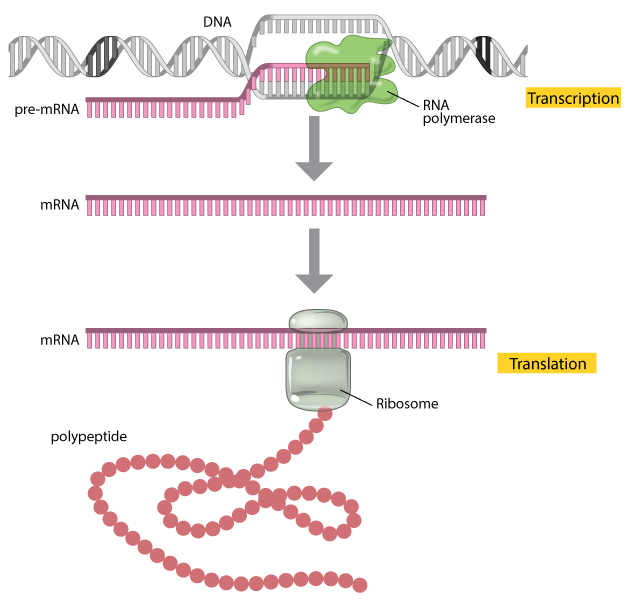
Figure 3.1: A gene is expressed through the processes of transcription and translation. Image source: Translation: DNA to mRNA to Protein
A common analogy is to think of DNA as a recipe book - containing the instructions necessary for life. RNA can be considered as a copy of a single recipe and protein as the final product of the recipe.
The central dogma of molecular biology is commonly stated that genetic information flows one way from DNA to RNA to protein.
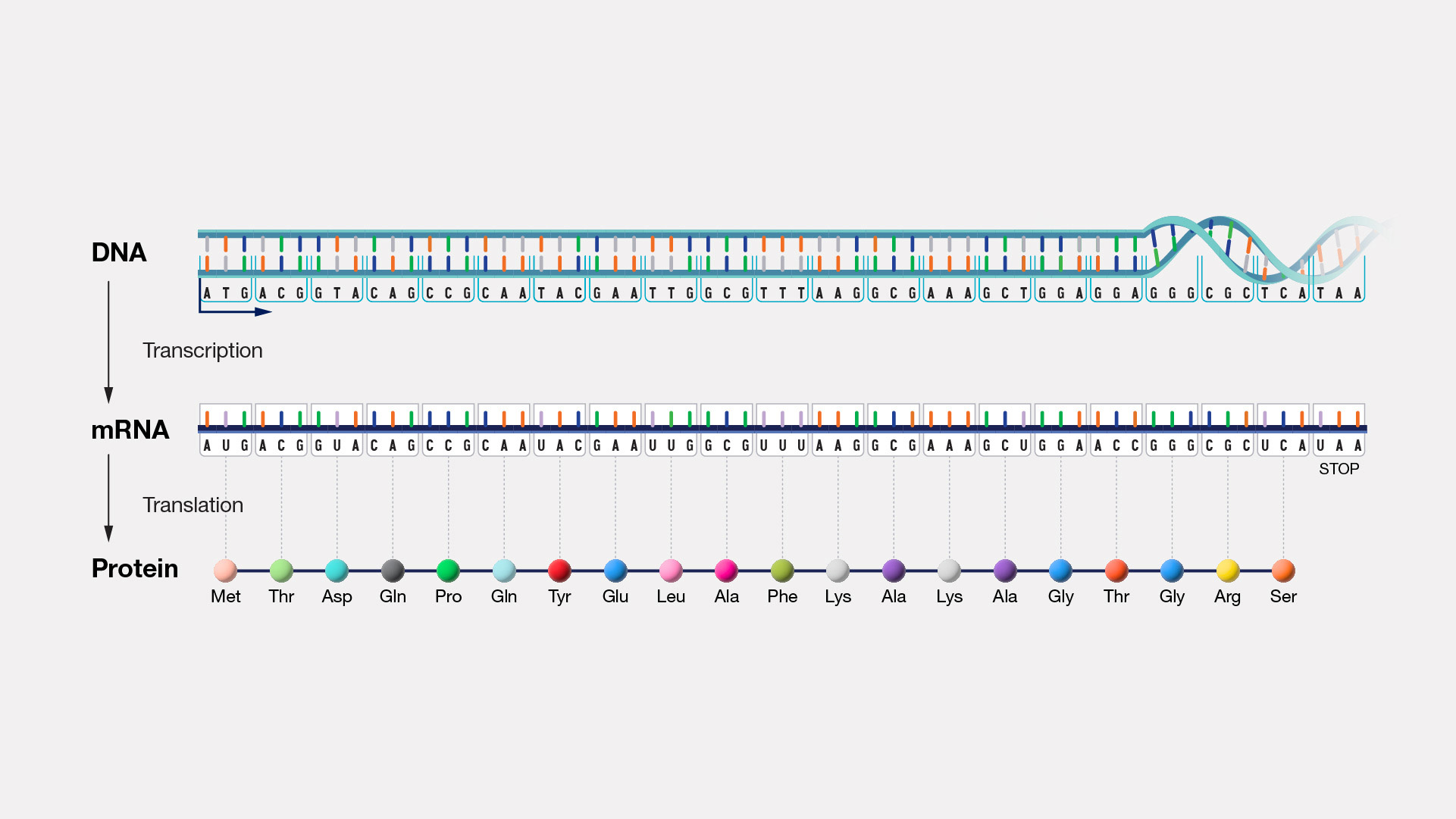
Figure 3.2: Central Dogma of molecular biology. Image source: NIH
The production of proteins is carefully orchestrated. A cell does not produce each protein encoded in its DNA at the same time, instead the expression of proteins is controlled. A kidney cell and a brain cell have the same DNA and yet their function is different. The diversity of cells produced by an organism arises from the expression of different combinations of genes and with different efficiency.
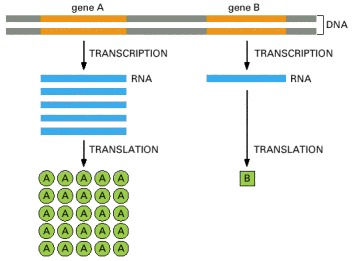
Figure 3.3: Genes can be expressed with different efficiencies. Image source: Molecular Biology of the Cell: From DNA to RNA
To study the genes controlling the functioning and development of cells and tissues in an organism, the RNA can be extracted and sequenced from a tissue. This allows us to understand which genes are being expressed in that tissue and which aren’t.
3.2 What Is RNAseq
RNAseq is a next generation sequencing technique for profiling all or selected RNA molecules in a tissue from an organism. It typically involves isolating RNA, converting to cDNA, ligating adapter sequences to the cDNA then amplifying by PCR to construct a library that can be used for sequencing. The reads generated by a sequencing machine are then aligned to a reference genome and can then be used for analysis.
A diverse ecosystem of protocols and technology exist that can be used to generate RNAseq data, which can be used in a wide variety of applications.
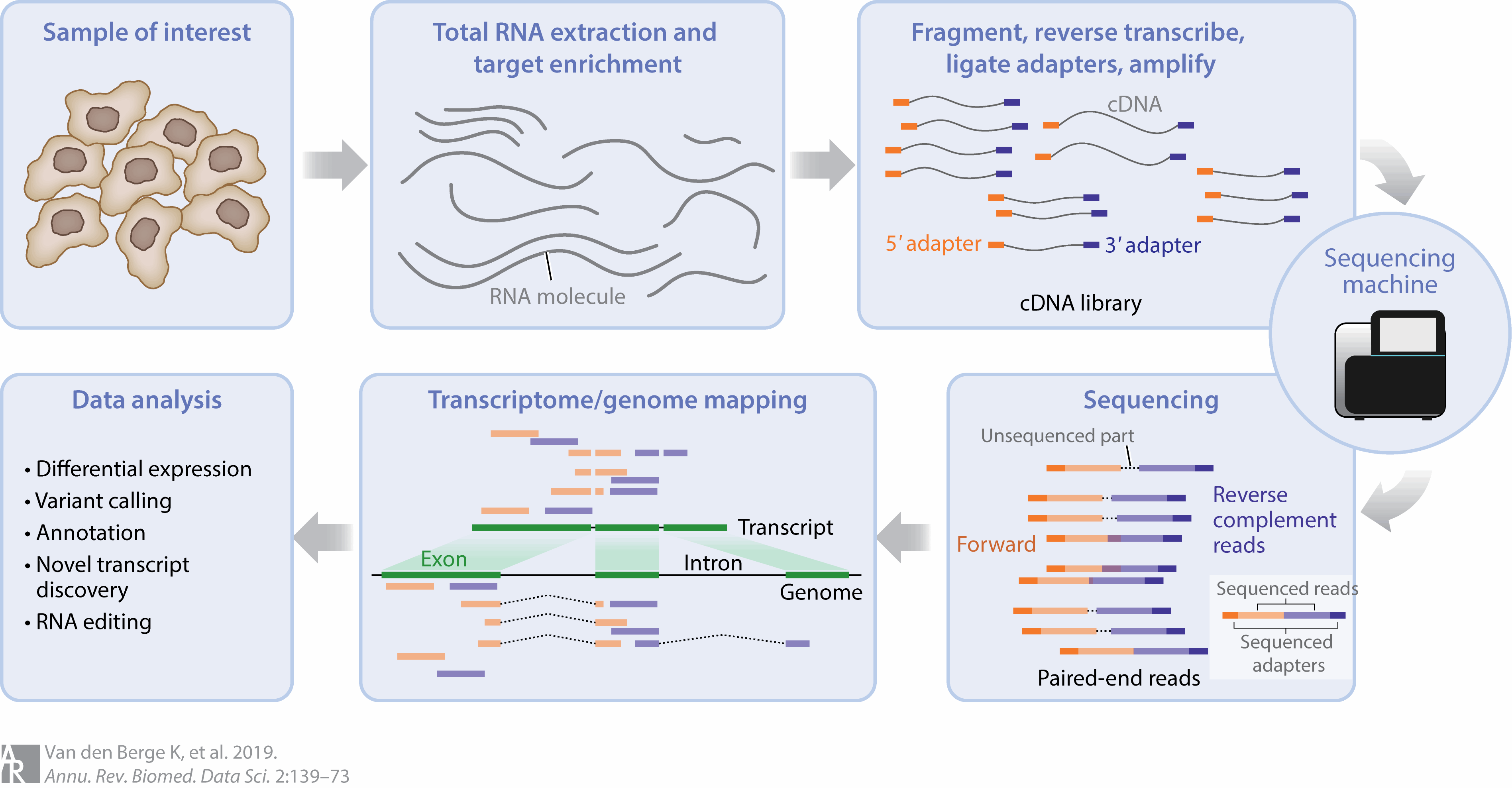
Figure 3.4: Overview of the steps in an RNAseq experiment. At each of these steps, there are choices that are made that can influence the final output of the experiment. Image source: RNA Sequencing Data: Hitchhiker’s Guide to Expression Analysis, 2019
What is a sequencing machine doing?
A sequencing machine generates a readout of the nucleotides that make up a DNA fragement. The most common type of sequencing is Sequencing by Synthesis which involves the use of unique fluorescently labelled nucleotides. These nucleotides are added one at a time and every time one of these nucleotides are added to a strand of DNA, the fluorescence emitted is detected by the sequencing machine.
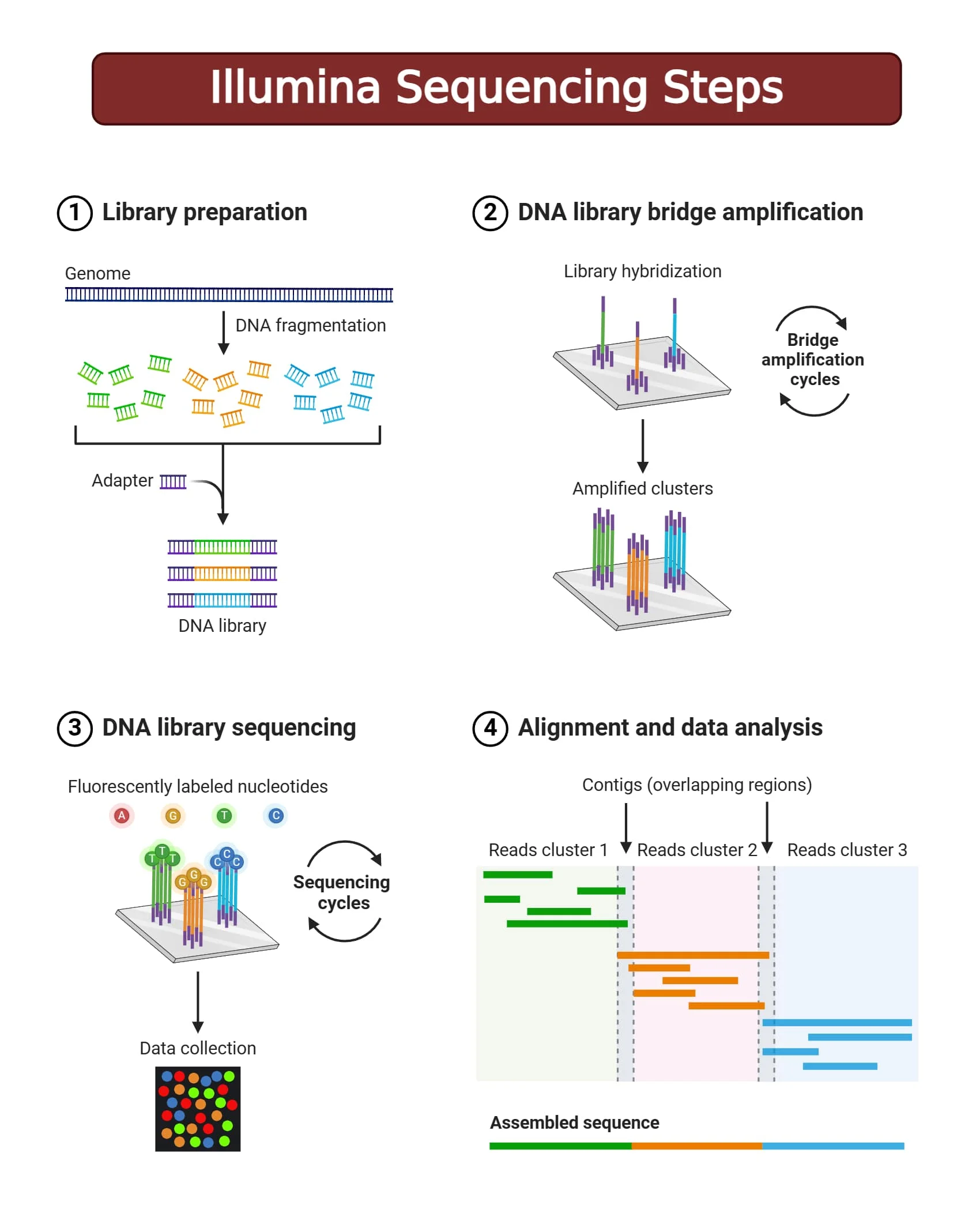
Figure 3.5: Illumina Sequencing by Synthesis. Image source: Microbenotes: Illumina Sequencing
3.3 Planning an RNAseq Experiment
The first step of planning an RNAseq experiment is asking whether RNAseq will answer the intended research question and whether it should be performed. Sequencing experiments are not cheap and a lot of time and money can be saved by ensuring that the sequencing experiment performed is suited to answering the research question at hand. There is a huge diversity in what RNA-seq can achieve due to the number of different protocols that have been developed and published. Therefore having a clear experimental goal will help in selecting an appropriate protocol that will best answer the research question as well as a good experimental design that will allow you to get the statistical power to answer that question.
There are some main considerations to planning an RNAseq experiment:
- What is the research goal?
- What is the budget for the proposed experiment?
- What sequencing technology will be used - can the selected protocol answer the research question? Do you have access to this sequencing technology?
- What is the experimental design - will the number of collected samples have enough statistical power to answer the research question? Are there confounding factors that might obscure the effect of biology that we want to study?
- What sort of analysis can be performed with the data that has been generated from the experiment? Are there already established analytical workflows or are you going to need to do some ad hoc analysis?
Having a clear research goal guides subsequent choices in terms of the type of RNAseq performed and the number of samples. The second most important thing is your budget - as this will dictate which technology you use and the number of samples you can collect. The ideal protocol for answering your research question might be prohibitively expensive - so you may opt for a different protocol. The ideal experimental design may require more samples than you can either afford to collect or are able to collect due to multitude of factors including ethical approval or sample rarity. It is very common for RNAseq experiments to be limited in the number of biological replicates collected due to the cost.

Figure 3.6: While the basic principles of experimental design are always strongly encouraged, the principle of replication unfortunately is often discarded in the face of sequencing costs
A common question researchers often ask is whether to sequence more deeply or sequence more samples. More biological replicates will provide better estimates of variance and more precise measures of gene expression than sequencing to a greater depth. It is generally advised to sequence more samples rather than sequence deeply if the option is there as early studies showed that more replicates provided more statistical power to identify differentially expressed genes over sequencing to a greater depth.
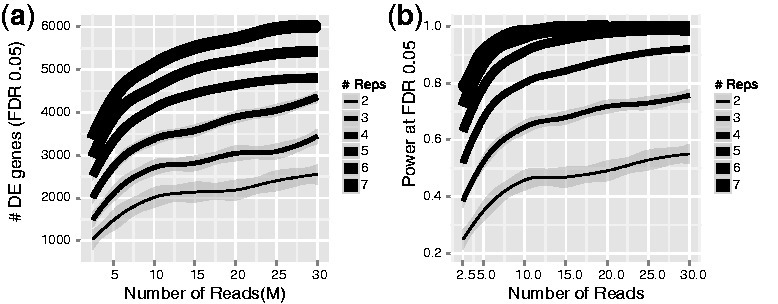
Figure 3.7: Biological replicates provide more statistical power to detect differential genes than sequencing depth. Image source: Liu Y et al, RNA-seq differential expression studies: more sequence or more replication? Bioinformatics. 2014
However, higher sequencing depth is necessary for detecting lowly expressed differentially expressed (DE) genes and for conducting isoform-level differential expression analysis.
There is no single RNAseq technology that is optimised for answering every research question - instead they may have different advantages, disadvantages and biases that can make one protocol better suited for a particular task over another.

Figure 3.8: There are many flavours of next generation sequencing machines that are available, with different chemistries and different sequencing methods.
There are many choices to be made in designing an experiment and it is easy to feel overwhelmed by these choices. Consulting with relevant experts such as sequencing providers and bioinformaticians prior to carrying out the experiment can aid in this process. It is also allows you to anticipate potential complexities that may arise in the analysis of the data and mitigate them. It might take several iterations and consultations to settle on a design that will achieve the most of your research outcomes. It’s also important to have an idea of how the generated data can then be analysed - will you be able to analyse it yourself or will you need to get someone else to do it?
The most common type of RNAseq experiment is using bulk short read sequencing for the purpose of identifying differentially expressed genes in a given tissue in an organism. This workshop has been designed with this understanding that this is the type of analysis that most researchers intend to perform but it is not the only application of RNAseq.
3.4 RNAseq Sequencing Protocols
RNAseq protocols can be described in a number of different ways. They can be classified as to the length of the reads produced by the technology, e.g either short or long reads. They can categorised by RNA captured for sequencing, e.g all available genes or if only a subset of target genes are used. More recently, with the development of single cell technology, they can now also be classified as the type of biological material they work with, ie is it at the single cell level or at a bulk tissue level.
These descriptions of RNAseq are not mutually exclusive and are in fact used in combination with each other.
| Biological material |
Entire tissue: Bulk RNAseq | Individual cells: Single cell RNAseq | |
|---|---|---|---|
| RNA tissue source |
Fresh | Frozen | FFPE (Formalin-fixed, paraffin-embedded) |
| RNA species sequenced | All RNA species captured: total RNAseq | mRNA only: mRNAseq | small RNA: small RNAseq |
| RNA isolation method | Ribosomal depletion | PolyA pulldown | Size selection |
| Read length | 50-300 bases: short read sequencing | 10-100kb: long read sequencing | 100-300kb: ultra long read sequencing |
| Library Strandedness | Original strand information not preserved: nonstranded library | Original strand information preserved: Stranded library | |
| Which end of the fragment is sequenced |
1 end: Single end sequencing | Both ends: Paired end sequencing | |
| Commercial platforms | Illumina, BGI Genomics, PacBio, Oxford Nanopore, 10x, NanoString, etc |
3.4.1 Bulk & Single RNA Sequencing
When working with bulk tissue samples, the expression profiles of individual cells is lost. A specific cell type might express high levels for a particular gene while another cell type might have low expression for that gene. In such a situation, the average profile of that gene is captured instead across the tissue. To retain information about the individual cells, single cell sequencing protocols have been developed and become quite popular.

Figure 3.9: Differences between scRNAseq and bulk RNAseq. Image source: Classical Single-Cell RNA Sequencing: a comprehensive overview
There are trade-offs between bulk and single cell sequencing. Bulk RNAseq is cheaper and suited for projects where global expression changes is what the researcher is interested in and the heterogeneity of the tissue sample isn’t a concern or of interest to the researcher. Bulk RNAseq analysis tends to be less complicated and easier to perform.
Single cell RNAseq is suited for projects where tissue heterogeneity is of interest. It’s also ideal for stdying rare cell types, as the signal from such cells would be lost in a bulk tissue. It can be used for charaterising cell states, identifying cell markers and studying cell lineage development and differentiation. Fewer genes are detected in a single cell RNAseq experiment and the data is lot more variable. If you are working with sorted cell populations, there may not be much heterogeneity in the sample, in which case single cell RNAseq might be a very expensive way to go about answering your question.

Figure 3.10: Single cell vs bulk sequencing. Image source: Single cell vs bulk sequencing
3.4.2 Short & Long Read Sequencing
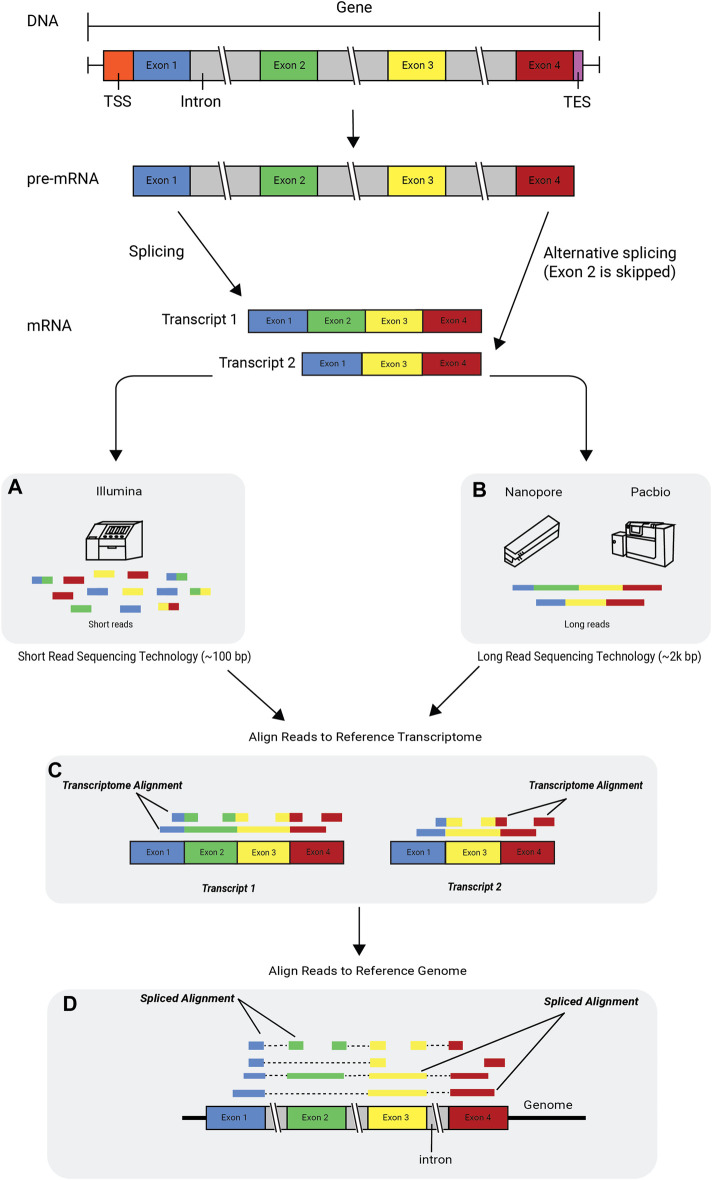
Figure 3.11: Alternative splicing and RNA technologies. Image source: Deshpande D, et al, RNA-seq data science: From raw data to effective interpretation. Frontier Genetics. 2023
Short read sequencing typically refers to protocols that fragment RNA into smaller pieces before converting to cDNA and sequencing. These are typically highly accurate and cost effective methods with well developed analysis workflows and pipelines. This type of data is commonly used for gene expression studies. Illumina and BGI are two popular short read sequencing providers.
Long read sequencing typically refers to technology that produce reads with length ranging from 10-100kb or 100-300kb (ultra long read). Long read sequencing can capture the full length of mRNA transcripts, which is useful when examining changes in isoforms or when performing de novo transcriptome assembly. Capturing the full length of a read also means that the PCR amplification can be skipped, reducing the coverage biases introduced by PCR. Long read sequencing historically has had lower read accuracy, high read length variability and lower throughput than short read methods but the technology has been improving over the past decade. Oxford Nanpore and PacBio are the leading long read sequencing technologies.
3.5 What Can RNAseq Be Used For
RNAseq data can be used for a variety of purposes. Broadly speaking, it can be used in 2 different ways:
- qualitatively: what is expressed? (e.g genes, isoforms, specific exons, intron retention, gene fusions, etc). RNAseq provides annotation information.
- quantatively: how much is expressed? Usually we want to know if the abundance of a gene has changed in response to a variable. This is the most common use of RNAseq data.
This capability for simultaneous discovery and quantification at the whole transcriptome level is a key reason that cemented RNAseq as the technology of choice for studying RNA. Previous technologies such as microarrays used pre-defined probes based on known genes thus limiting their ability to discover new genes.
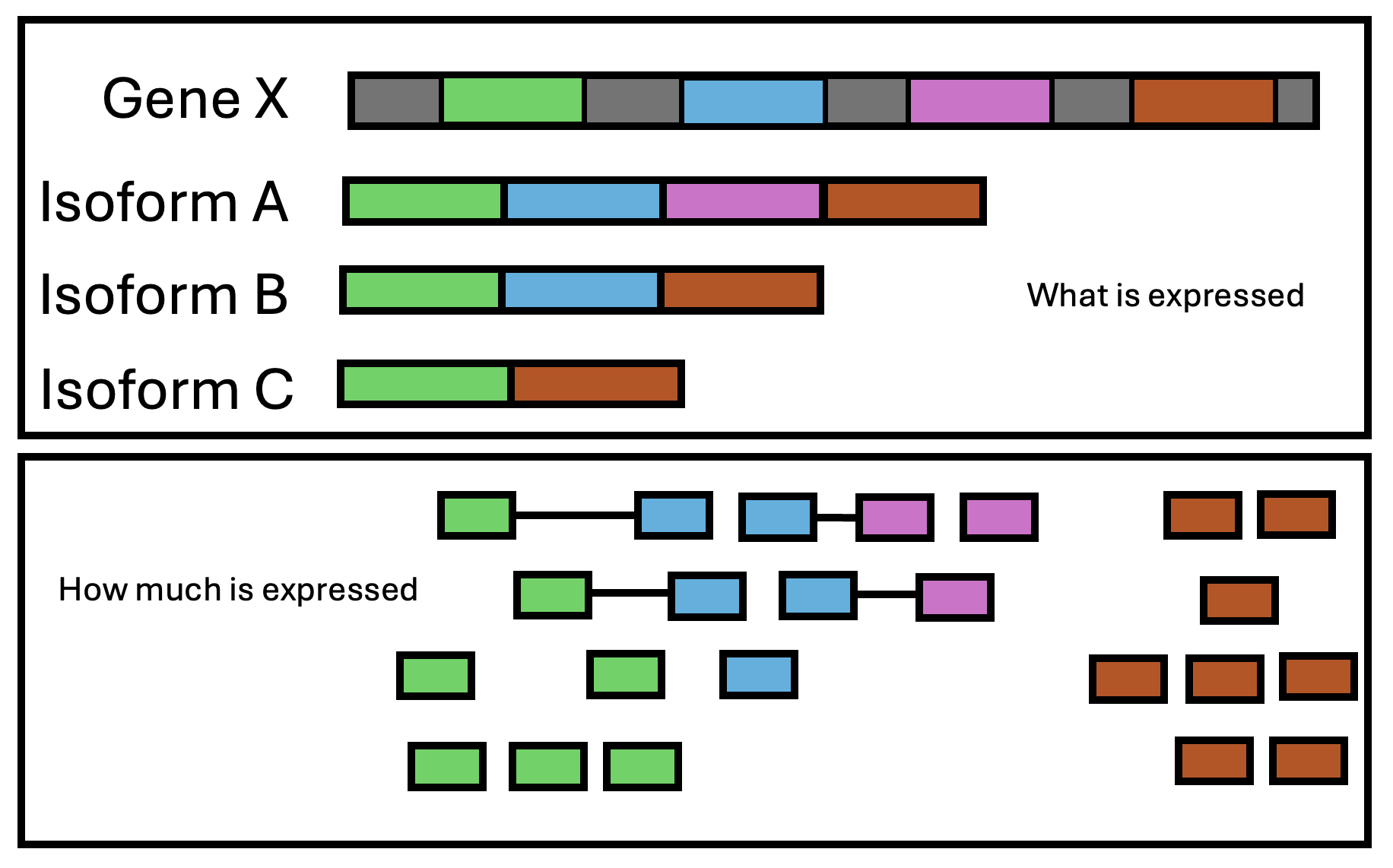
Figure 3.12: RNAseq captures two layers of information: what is expressed and how much is expressed
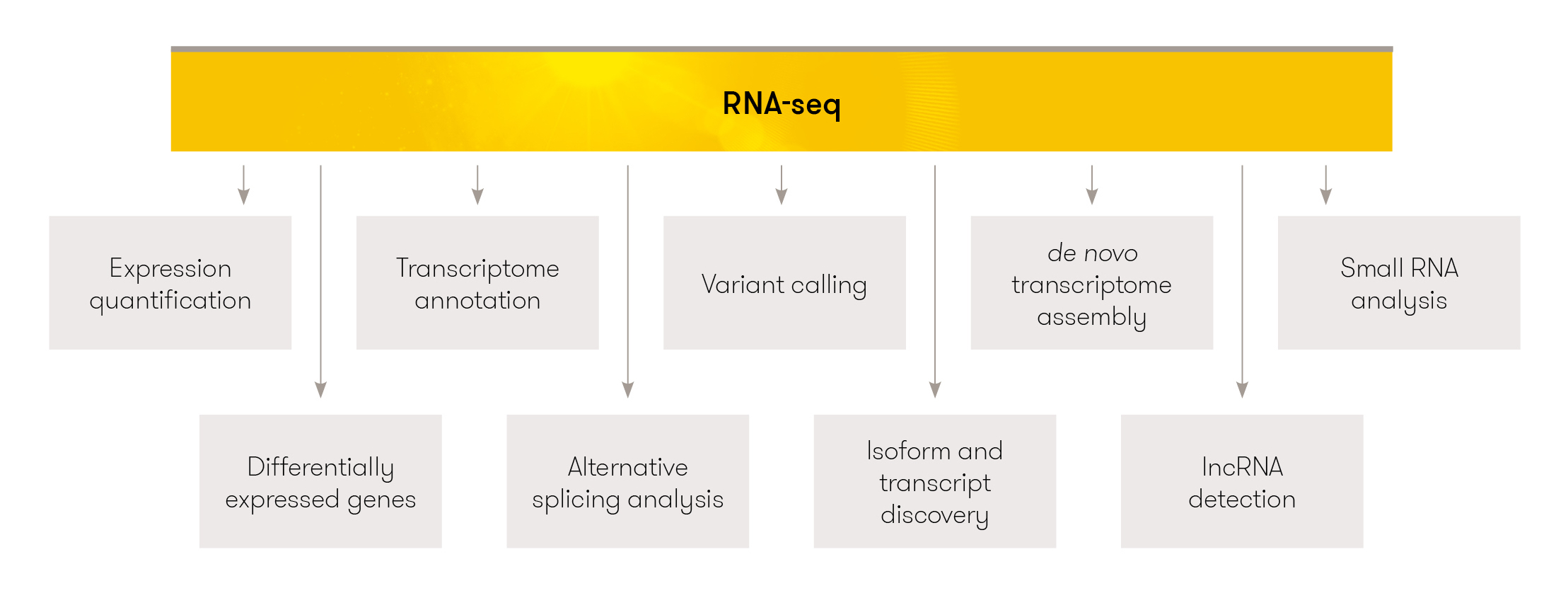
Figure 3.13: Image source: RNA-seq
Uses of RNAseq data:
- Differential expression analysis: differential gene expresssion (DGE), Differential Transcript Expression (DTE), Differential Transcript Usage (DTU)
- Novel transcript/isoform discovery: identify new transcripts/isoforms that are not annotated in a reference
- De novo transcriptome assembly: if a reference genome for an organism is not available, the information from RNAseq reads can be assembled into contigs to form a transcriptome for protein coding genes
- Detect alternate splicing/differential isoform usage, detect changes in isoform abundance
- Gene fusion detection
- Multiomic integration: combine transcriptomic data with other ’omic data such as DNA sequencing or epigenetic information
3.5.1 Differential Expression Analysis
The most common type of analysis performed with RNAseq data is differential gene expression (DGE) analysis. This type of analysis looks at the difference in abundance for genes between 2 or more conditions. The conditions should have a suitable control condition that provides a baseline measurement that another condition can be compared against.
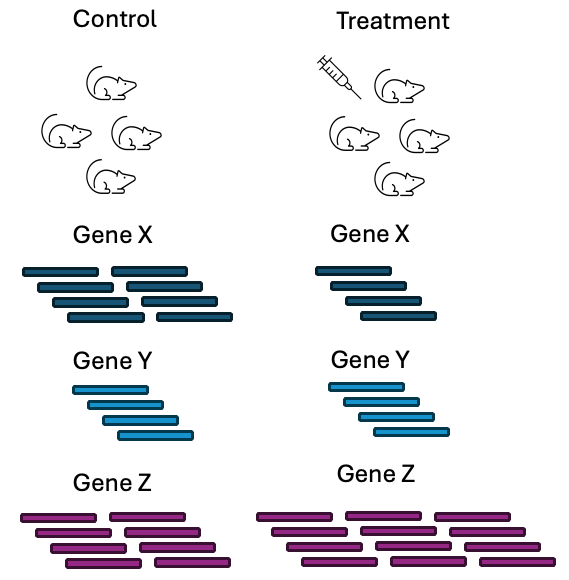
Figure 3.14: A basic DGE analysis asks which genes have a statistically significant difference in abundance between two conditions
After identifying differentially expressed genes, it is common to perform some type of pathway enrichment analysis or gene set enrichment to find molecular pathways or biologically processes that these genes are involved with. This can allow the researcher to identify trends that might be hard to notice when looking at individual genes.

Figure 3.15: Dotplots of the results from overrepresentation anaylsis (ORA) and gene set enrichment analysis (GSEA). Image source: Biomedical Knowledge Mining using GOSemSim and clusterProfiler
While DGE is the most common type of analysis performed on RNAseq data, it is not the only type of differential test that can be performed with RNAseq data. DGE analysis ignores what is happening at the isoform level and looks at global gene abundance changes only. Instead, an RNAseq dataset can be analysed to look at changes at the transcript level, to see if the change in conditions is also affecting multiple isoforms for a gene differently.
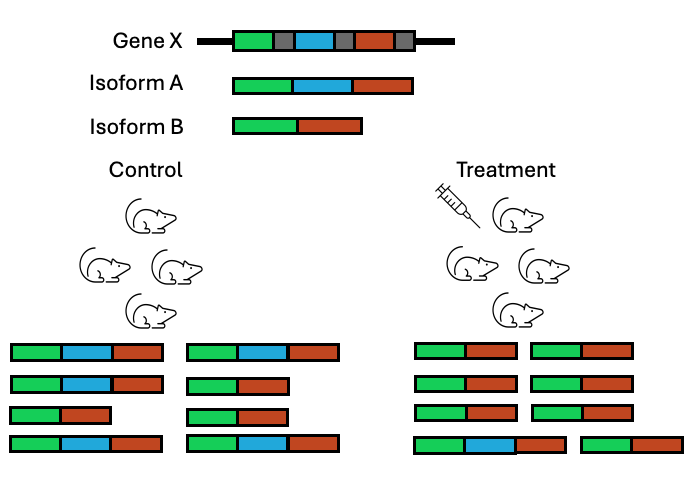
Figure 3.16: In a DGE analysis, this gene might be ignored for having no change in expression when actually a switch is occuring amongst the isoforms that are being produced
Additionally, we can look at whether transcript levels are changing between two conditions, regardless of the gene of origin. This is known as differential transcript expression.
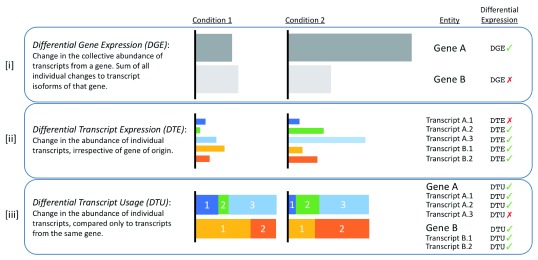
Figure 3.17: The types of differential expression analysis. Image source: Froussios K, et al, Relative Abundance of Transcripts (RATs): Identifying differential isoform abundance from RNA-seq. F1000Research. 2019
If interested in transcript changes, the complexity of the analyses can be determined by the choice of short or long read sequencing. While short read sequencing can be used for both, there is additional complexity when used for transcript level analysis as many reads will map ambigiously for transcripts. There are methods that have been developed for probabilistically assigning reads to transcripts.
Long read sequencing can be more suited for isoform/transcript level analyses than short read sequencing as there is less or no ambiguity to which isofrom a read comes from, if the entire transcript has been sequenced.
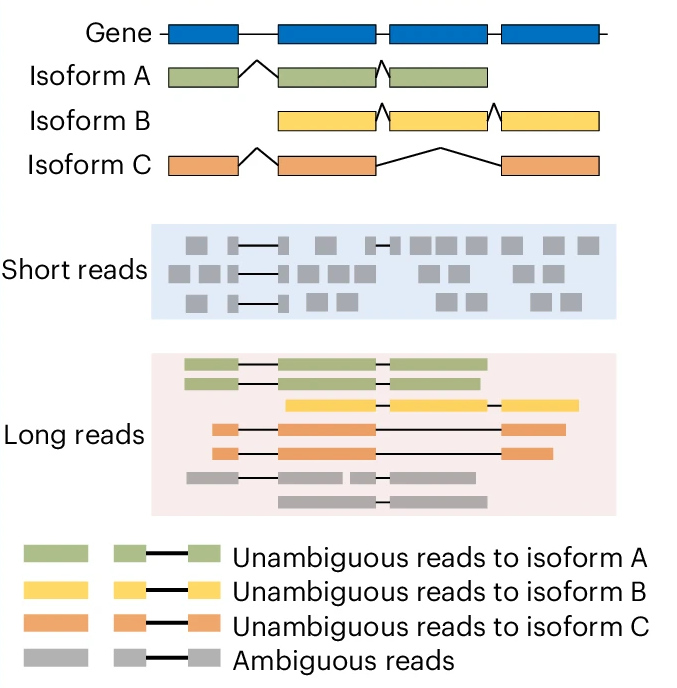
Figure 3.18: Short reads can be ambigious as to which isoform they belong to. Long reads have less uncertainty. Image source: Improving gene isoform quantification with miniQuant, 2025
3.5.2 Using RNAseq Data For Annotation Purposes
3.5.2.1 Transcriptome Assembly
Most RNAseq datasets are used for quantative analysis - the data is aligned to a pre-existing reference genome and pre-existing annotations. However, these resources do not exist for every organism. When a reference genome is either unavailable or the reference available is not adequate, it is possible to take RNAseq reads and assemble them into a transcriptome of the assayed organism. In such situations, RNAseq data has a dual purpose - the reference transcriptome is built from the sequences of the reads and then the reads are counted against the transcriptome for differential analysis.
Assembling a transcriptome can be done in 2 ways, there are reference based methods and de novo methods. Reference based methods use the reference of either the organism or a closely related species.
De novo assembly methods are reference free - this is useful when studying non-model organisms as often they lack well annotated reference genomes.
A combination of long read sequencing & short read sequencing is best suited to building high quality transcriptomes than either alone. Short read sequencing has high accuracy and fewer errors while the longer read length retains more information and context about the original RNA molecule.
A commonly used analogy when describing assembly is to imagine the genome/transcriptome as a puzzle that needs to be put back together. The smaller the pieces, the more difficult the puzzle. A puzzle made of larger pieces is much easier to put back together and reconstruct the original RNA sequence.
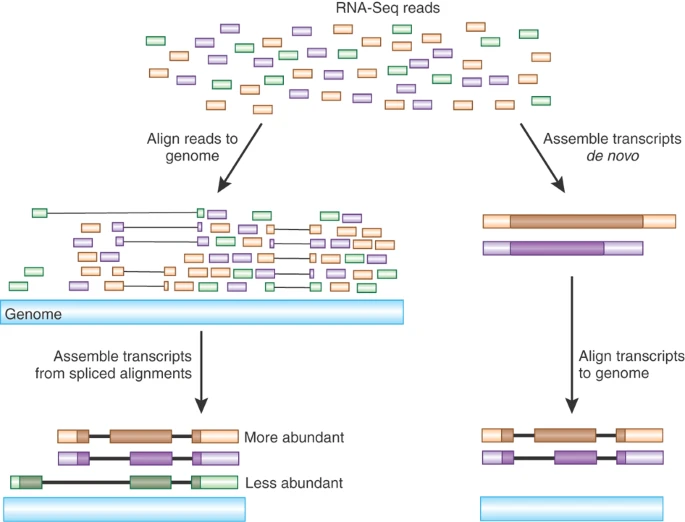
Figure 3.19: Strategies for reconstructing transcripts from RNA-Seq reads. Image source: Advancing RNAseq Analysis (2010)
3.5.2.2 Novel Transcript/Isoform Discovery + Gene Fusion Detection
Transcriptome assembly is usually performed in situations when working with organisms that lack reference genomes and annotations. However, even with well annotated and studied organisms, there are still plenty of uncharacterised transcripts that haven’t been discovered or described. Novel transcript discovery can help refine existing annotation resources.
This also has clinical applications. One such application is the detection of fusion genes - these can arise due to chromosomal rearrangements combining the coding regions of two genes. These genes can produce aberrant proteins and lead to cancer development if the fused genes are oncogenes or tumor suppresor genes. Therefore, detection of fusion genes can be an important diagnostic tool in clinical settings as well as for cancer research.
Optional Discussion: Design A Bulk RNAseq Experiment
You want to examine the impact of several different growth conditions in a specific bacterial strain and you are interested mostly in changes to gene expression. A side goal of your project is to look at small RNA changes. Assuming you have no limitations on your budget, what are some considerations you’d have in designing a potential RNAseq experiment for this project?
3.6 Before you begin an experiment: some questions to consider…
The questions below are a few that might help in planning an experiment:
- do you want to assay changes in gene expression?
- do you want to identify novel transcripts?
- do you intend to study transcriptomic changes in individual cells or the tissue level? (single versus bulk RNAseq)
- do you want to characterise isoforms/study alternative splicing? (short versus long read sequencing)
- will you pull down transcripts with a poly A tail (poly-A selection) or deplete ribosomal genes (ribo depletion)? Does your organism produce mRNA with a polyA tail?
- single end or paired end sequencing?
- does your organism of interest have an annotated reference genome or will you need to assemble a transcriptome?
- are you going to align against the genome or transcriptome?
- how many different conditions are you testing? How many replicates do you have for each condition? Do you have a control condition?
- how complex is the experiment? Will you be able to collect all the samples you need in one experiment or are you going to have to do multiple batches?
- how inbred is your organism? If the organism of interest is not inbred, what level of genetic variation exists between your individuals?
- what is your budget? How many samples can you afford to sequence?
- does the data have already established analysis workflows or are you going to have to do it from scratch?