6 Pipeline Overview
6.1 High-level
An RNA-seq pipeline needs to identify which RNA transcript a sequencing read has originated from to quantify transcription of genes.
Once we know the origin of each read, we can use this to estimate the abundance of each transcript.
The minimal inputs to an RNA-seq processing pipeline are:
- a set of raw reads (typically in gzipped FASTQ format)
- a reference genome sequence (FASTA, gzipped) and gene annotations (GTF or GFF3, gzipped)
At the high-level, a pipeline aims to:
- align or ‘map’ the read to the genome (or transcriptome)
- (mRNA transcript, exon, intron, or somewhere else on the genome ?)
- count reads associated with features to quantify (differential) abundance
Counts of the number of reads associated with each feature (gene) are used to estimate the relative abundance of transcripts, and find differences in gene expression between groups (== differential expression analysis).
Usually we quantify expression per gene (the sum of all transcripts arising from that gene).

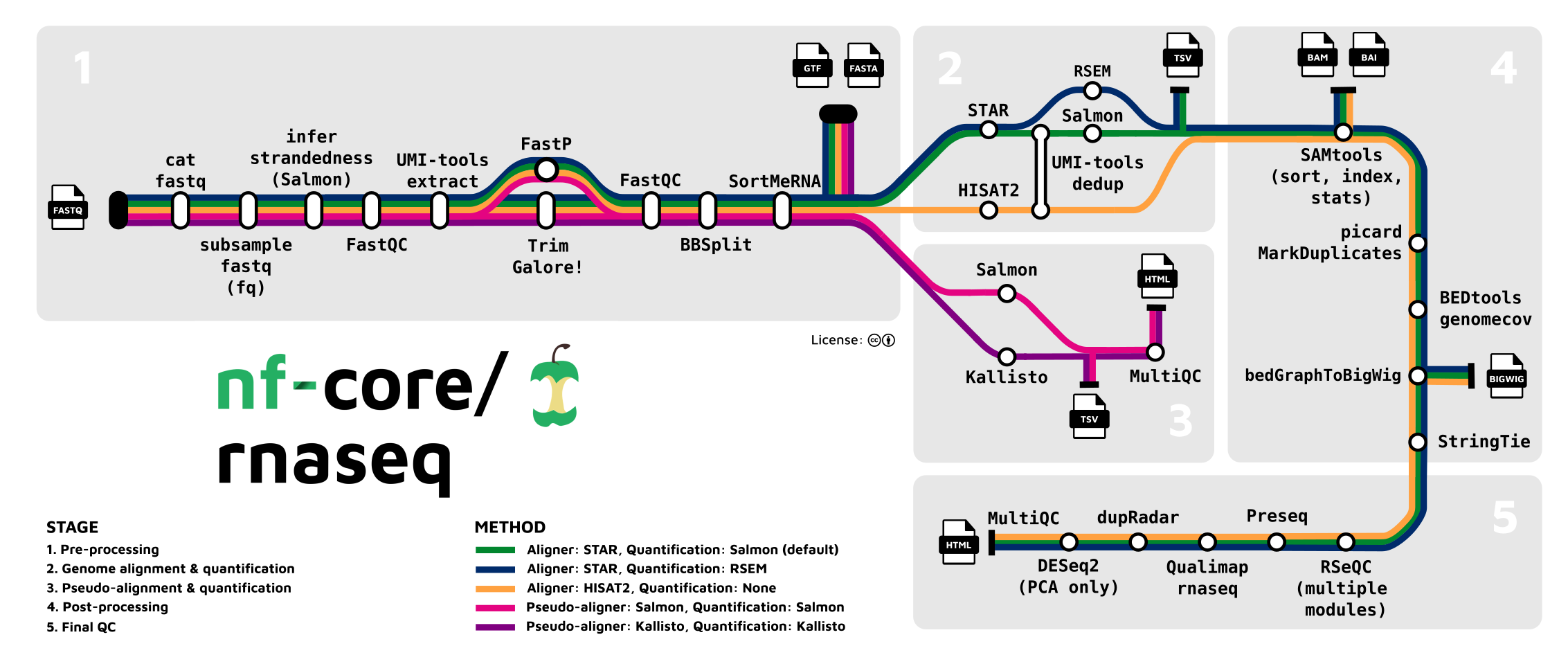
6.3 A more complex pipeline
Laxy demo
We often run the nf-core/rnaseq pipeline via the Laxy web interface, developed within the Platform.
Don’t start your own run right now ! I’ll work through a demo - you can try yourself later.
6.3.1 Optional: Pipeline activity
Challenge: Create your own fantasy RNA-seq processing pipeline
There are many different ‘tools’ that can be composed into an RNA-seq processing pipeline. Many do pretty much the same thing, each with trade-offs on speed, accuracy, memory, features etc.
Compose a set of tools in an order that might make an RNA-seq pipeline.