17 Novel species FEA
FEA can be easily performed for many non-model species with user friendly web tools or R packages. g:Profiler web currently supports 984 species, and STRING currently supports over 12 thousand species.
Since many non-model species are supported by some FEA tools, today I am using the term novel species to describe a species that is not currently supported by any FEA tool.
Novel species FEA is possible with clusterProfiler or WebGestaltR in R, or using web tools WebGestalt or STRING. The requirements for each tool are slightly different, however at minimum a predicted proteome fasta is necessary. If you do not have a predicted proteome for your species, you would need to perform gene prediction, for which there are a number of in silico tools available. It must be kept in mind that in silico predicted proteomes can vary greatly in quality. Those that include multiple data sources such as polished genome assemblies generated with both short and long read shotgun sequencing and gene prediction that includes RNAseq data are likely to produce better gene predictions than those that are based only on for example short read sequencing.
Workflow overview of novel species annotation
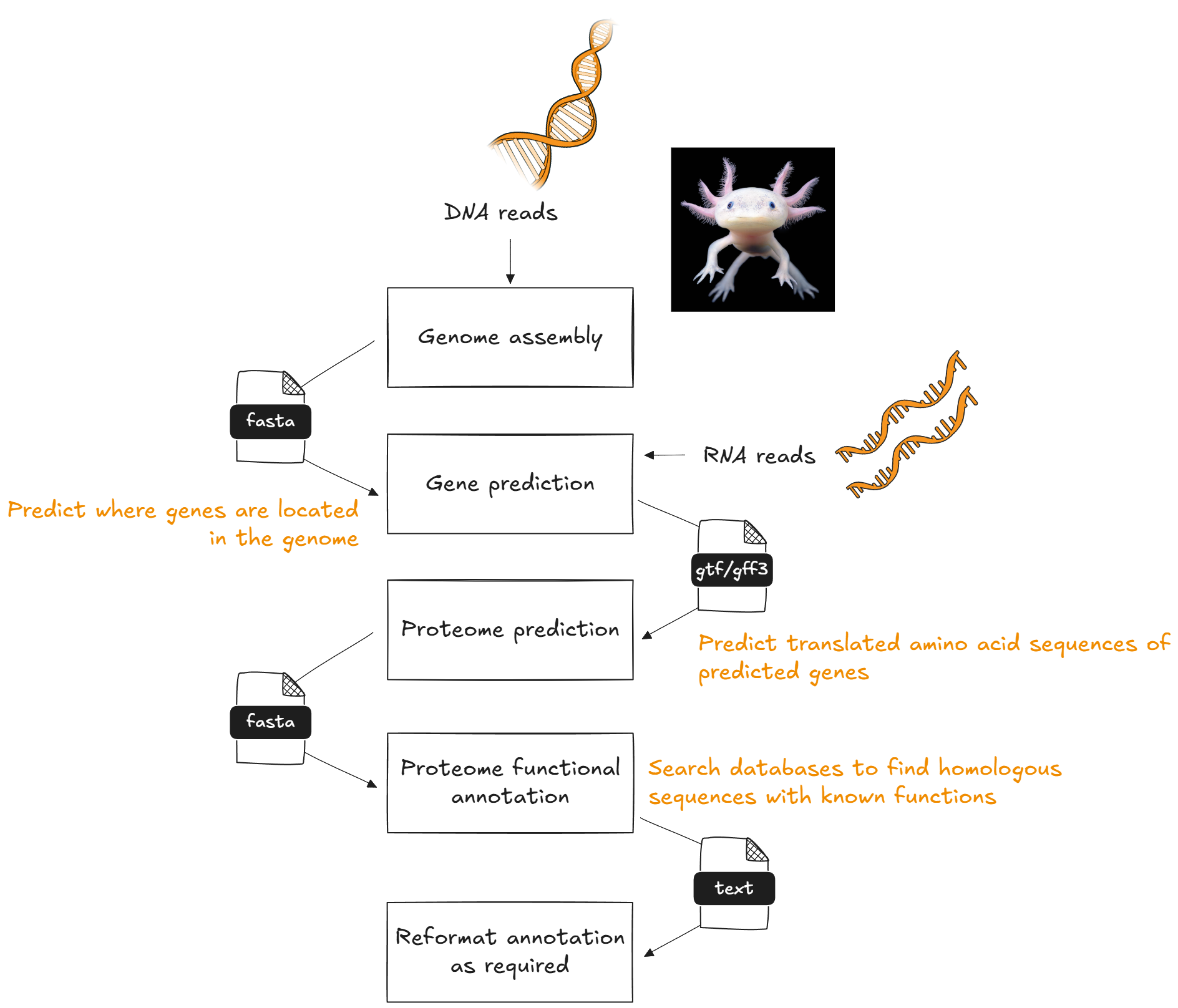
In this activity, we will use all three tools to perform FEA on a species that has a publicly available reference genome and gene predictions, but is not currently supported by any web-based FEA tool.
For clusterProfiler and WebGestaltR, we will import and reformat an annotation text file to match the requirements of the tools.
For STRING, we will use a STRING annotation on the web tool.
17.1 Axolotl functional enrichment analysis
17.1.1 Background
The axolotl (Ambystoma mexicanum) is a salamander with some very cool abilities: it can regenerate damaged or amputated tissue, including spinal cord and some brain regions. While this species has reference genome on NCBI, it is not annotated. There is no axolotl Org.db Bioconductor annotation package available nor does this species exist in KEGG Organisms. There is however an axolotl genome browser where you can download a (slightly less contiguous than the NCBI version) reference genome plus a (non-curated) GTF file.
Despite the lack of quality resources, there is much ’omics work conducted in axolotl due to its regenerative capabilities.
Today we will use public RNAseq data from axolotl, comparing gene expression in the blastema after proximal (at the shoulder) and distal (at the hand) limb amputation. The blastema is a collection of undifferentiated progenitor cells that give rise to the regenerated limb. Maybe our functional enrichment analysis of differentially expressed genes can help us understand processes that cause the blastema to grow into a full limb or just a hand!
17.2 Caveat!
This is not a real experiment! It was tricky to find a novel species that had:
- a reference genome
- a GTF
- was not natively supported by any FEA tool
- had publicly available RNAseq data
- FEA described in a peer-reviewed study
This axolotl data ticked A through D yet not E (RNA from various tissues were sequenced to aid a genome assembly project rather than for a valid biological experiment). Please keep this in mind when reviewing the results of the FEA we perform 😉 The goal of the session is not really to uncover how a blastema differentiates into a hand or an arm, but to demonstrate to you how you can apply this method to your own novel species.
17.2.2 Data preparation
17.2.2.1 Annotation files
The reference genome and GTF gene prediction file were downloaded from www.axolotl-omics.org. A proteome was created by extracting the predicted peptide sequences from the GTF then retaining the longest isoform per gene with AGAT v 1.4.0. The predicated proteome was then annotated with eggNOG emapper v 2.1.12.
The annotation output file has been provided to you, and we will import this into R and use the dplyr package v 1.1.4 to extract GO and KEGG IDs into the required format for R-based FEA with clusterProfiler and WebGestaltR.
The predicted proteome was also annotated with STRING v 12.0. As of version 12, STRING includes a feature Add any organism to STRING / Annotate proteome (Szklarczyk etl al 2023). The axolotl proteome was uploaded to STRING and annotation performed on STRING servers in less than 1 day. The resulting annotation is persistent and shareable and can be used for all of STRING’s search functions including ORA (Multiple proteins) and GSEA (Proteins with Values/Ranks).
17.2.2.2 Reads processing and differential expression analysis
Broadly following https://github.com/Sydney-Informatics-Hub/RNASeq-DE, The raw RNAseq fastq were downloaded from Bioproject, quality trimmed and adapters removed with BBtools bbduk v 39.01, then aligned to the reference genome with STAR v 2.7.11b. Feature counting was performed with HTSeq-counts v 2.0.3 and formatted into a counts matrix. Differential gene expression analysis was performed in R with DESeq2 v 1.46.0, filtering for genes with at least a count of 10 in at least 2 samples. The data comprises 2 groups (proximal blastema and distal blastema) and 2 replicates per group.
The DE results file has been provided to you, and we will import this into R to extract our gene lists.
17.3 Activity overview
- Import
emapperaxolotl annotation file, GO ontology file and KEGG Pathways file - Import axolotl DE results file and extract gene lists for ORA and GSEA
- Reformat annotation files for
clusterProfilerGO and KEGG analysis - Run
clusterProfileruniversal FEA functionsenricherandGSEAand visualise results withenichPlot - Reformat annotation files for
WebGestaltRGO and KEGG analysis - Run
WebGestaltRORA and GSEA and visualise results in the interactive HTML report - Run ORA with
STRINGonline using custom axolotl annotation - Compare
STRINGORA web results to those generated using theemapperannotations in R
Before heading over to RStudio, we will briefly review the annotation requirements for the R tools. At the end of the R-based analysis, we will return here for the web-based analysis with STRING.
17.4 R-based FEA
17.4.1 clusterProfiler
This tool can perform ORA or GSEA for any organism with the provision of custom TERM2GENE and TERM2NAME files. TERM2GENE maps the species gene ID to database (eg GO, KEGG) terms, and TERM2NAME maps the terms to their descriptive names. The gene IDs for our axolotl annotation are prefixed with AMEX60DD.
Example TERM2GENE format:

Example TERM2NAME format:

These are then provided to the universal enrichment functions GSEA and enricher (ORA). It is essential that the gene lists provided have the same gene IDs as those in the TERM2GENE file.
In RStudio, we will extract these file formats from the emapper annotations file for axolotl and proceed with FEA.
We are using GO and KEGG today, however you can use any database, provided you first annotate your proteome to the database in order to obtain the term to name mappings.
Acknowledgement to Armin Dadras for sharing his code to extract TERM2GENE and TERM2NAME from emapper output.
17.4.2 WebGestaltR
This tool can perform ORA or GSEA for any organism with the provision of custom GMT and description files.
The GMT file format is slightly different than the typical gene set matrix transposed file format you may have seen before, which typically has the gene set description in the second column. For WebGestaltR, the description is in a separate file, and the tab-delimited GMT file with .gmt suffix has these 3 columns:
- Gene set ID
- Web link for gene set
- Third and subsequent columns are genes belonging to the gene set
Example .gmt format:
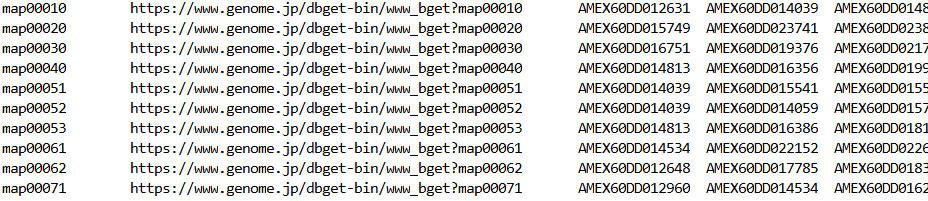
The WebGestaltR tab delimited description file with .des suffix has these columns:
- Gene set ID
- Gene set description
Example .des format:
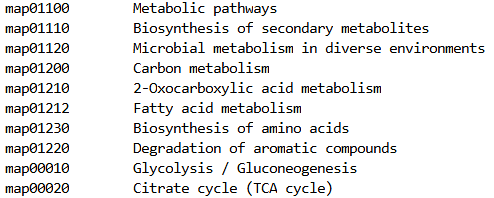
These files are then provided to the single FEA function within the package. The function has the same name as the package - WebGestaltR. Users control the analysis type by providing one of ORA, GSEA or NTA arguments to the parameter enrichMethod.
The .gmt file is provided to the parameter enrichDatabaseFile and the .des file is provided to the parameter enrichDatabaseDescriptionFile. Specifying organism = "others" is also required to run the FEA analysis with the custom databse files. It is essential that the .gmt file has the same gene IDs as those in query gene list.

17.4.3 Mapping database terms to descriptions
Annotating a proteome with a tool such as emapper provides a connection between your novel species gene IDs and term IDs. To add the term description, we need a database file. In this analysis, we will use the GO ‘core’ ontology file and the KEGG Pathways file. These files were downloaded to the workshop folder of the VMs during our setup session.
The GO go.obo is a text file (>600K lines) with details for all terms in GO at the time of download. The second line of the file contains the GO database version, in this case: data-version: releases/2024-06-17.
go.obo term information is structured like this:

The KEGG Pathways file is identical in format to what is required for both the clusterProfiler TERM2NAME and WebGestaltR .des files:
KEGG Patwhays file format:
17.5 RNotebook novel species FEA
➤ Go back to your RStudio interface and clear your environment by selecting Session → Quit session → Dont save → Start new session
➤ Open the notebook novel_species.Rmd.
We will now continue with the activity in RStudio, before returning here to finish up with STRING web-based analysis.
💫 You have now explored two tools performing FEA in R for your novel species, and we have observed that both methods require the same starting files (annotation of novel species genes to databases, database term IDs to term descriptions) and give very similar results. Which you use depends on your personal preferences.
- Do you enjoy the flexibility of plot options offered with
clusterProfilerandenrichplot? - Do you love the ease of use and interactive HTML provided by
WebGestaltR?
We will now take a quick look at novel species FEA online with STRING.
17.6 STRING (web) novel species FEA
The axolotl putative proteome was previously uploaded to STRING and custom annotation performed. This completed using the STRING servers, with compute time less than one day.
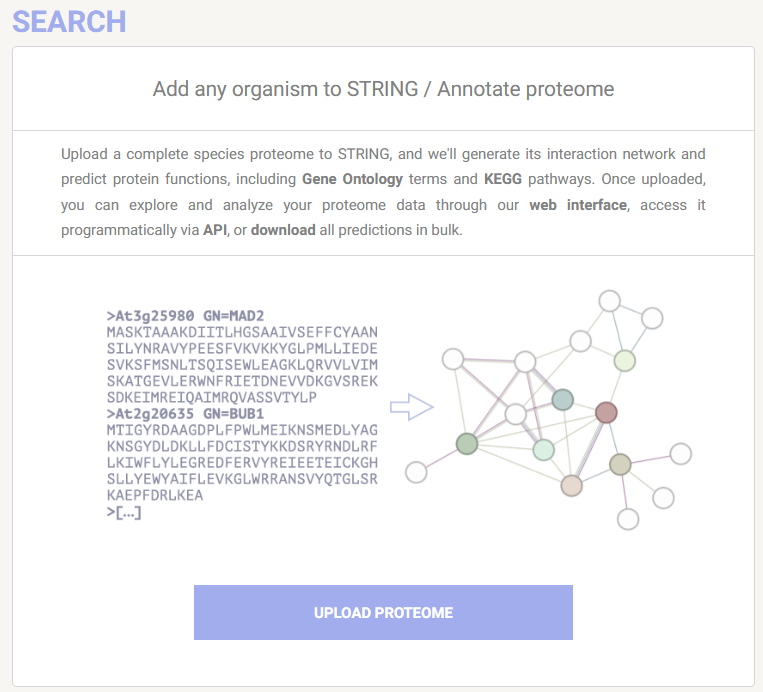
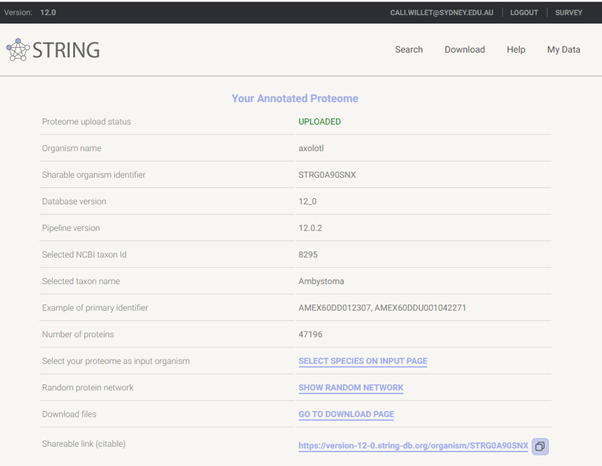
Using the STRING web tool, we will now peform ORA of this custom axolotl annotation. We will not perform GSEA on STRING purely in the interest of time, as the processing takes a lot longer than ORA, however if you wish to run this at a late date, please go ahead! The axolotl annotation link is persistent and citable, enhancing the reproducibility of your novel species FEA 🏆
➤ Open the following link in your browser:
https://version-12-0.string-db.org/organism/STRG0A90SNX
STRG0A90SNX is the annotation ID assigned by STRING.
This link will take you to the axolotl annotation page, where you can click SELECT SPECIES ON INPUT PAGE to add the custom species to the Organisms field, then toggle to your desired search type.
There is also a downloads page, where any of the STRING annotation files can be downloaded. If you wanted to use the STRING annotation files in clusterProfiler or WebGestaltR, you would download the ‘protein enrichment terms’ file and then extract the terms and axolotl gene IDs into the required formats, as we did for the emapper annotations.
STRING protein enrichment terms file format:

➤ On STRING, click SELECT SPECIES ON INPUT PAGE, then from the left search options, select Multiple proteins.
Note that the Organism field is pre-filled with STRG0A90SNX (axolotl).
➤ In the RStudio Files pane, locate your saved ORA gene list from earlier - workshop/Axolotl_DEGs.txt. Click the file to view it in RStudio, then copy paste the list into the STRING List of Names search field, then select SEARCH
➤ Click CONTINUE at the gene ID review page
Before we explore the results, note that we have performed ORA without a background gene list! 😮
There is no option at the query page (even under Advanced Settings) to provide a custom background gene list initially. This must be done after the initial search has been run. Hopefully this will change in future versions 🫠
❗In order to add or apply a previously saved custom background gene list, you need to be logged in to STRING. The upload can take a bit of time, so you do not need to do this now, however the dropdowns below provide instructions for applying a saved background or adding a new one.
Add a saved custom background to STRING analysis
- After running ORA or GSEA, on the results page, click on the
ANALYSIStab - Scroll ALL the way to the bottom of the page to the subheading
Statistical background- If you do not have a relevant saved background gene list in your
STRINGsaved datasets, you would selectAdd background. See next dropdown for details - If you do have a relevant background saved, change
Whole Genometo the relevant gene background list from the drop-down menu
- If you do not have a relevant saved background gene list in your
- Once you have selected the background, click
UPDATEand the FEA will be re-computed using the custom statistical background

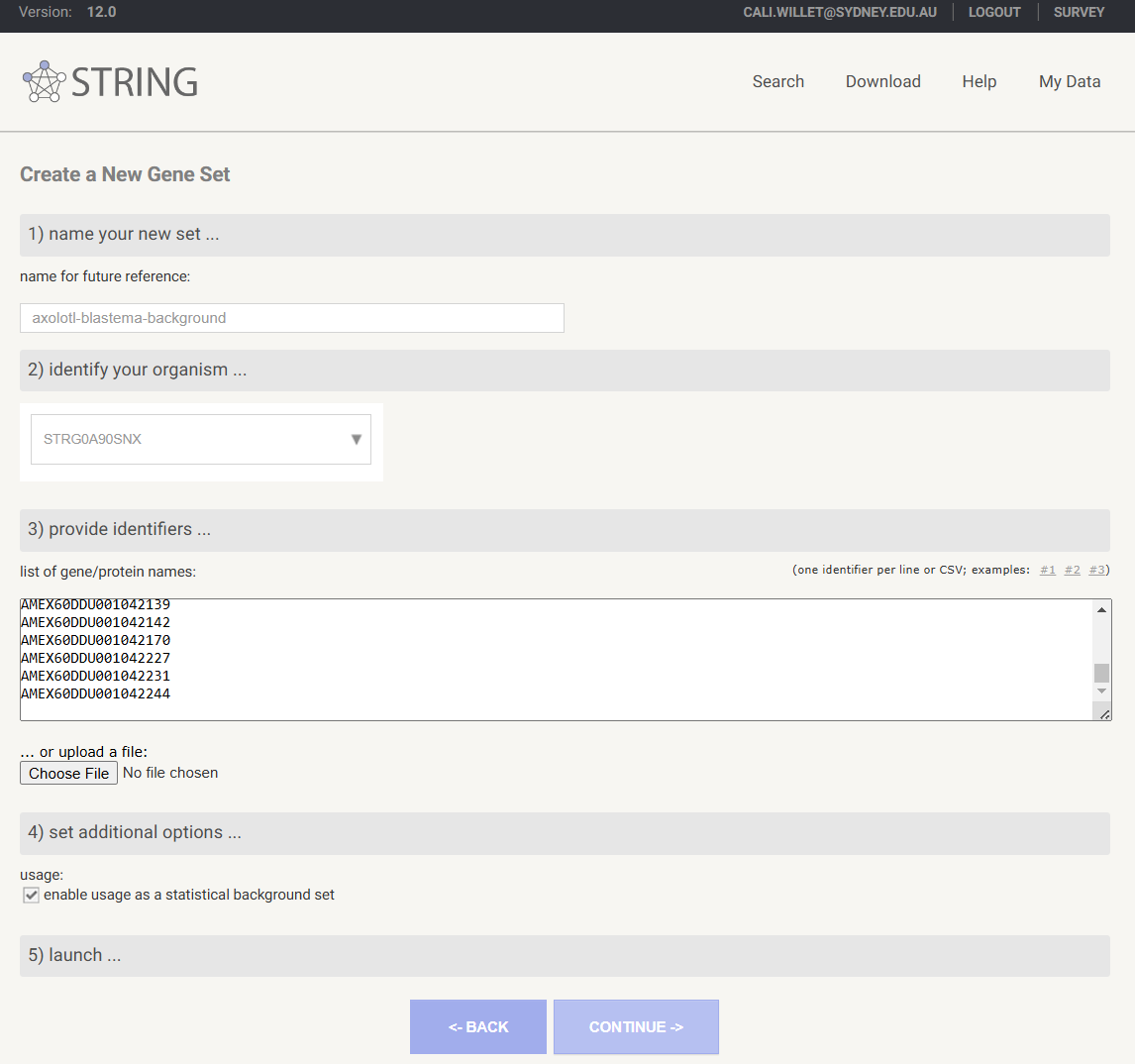
Save a new custom background gene list to your STRING profile
- Under
ANALYSIStab of results page, atStatistical background, selectADD BACKGROUND - You will be prompted to login if you are not already
- Under
1) name your new setprovide a descriptive name for your background gene list - Select your organism at
2) identify your organism - At
3) provide identifierscopy your list of background IDs into thelist of gene/protein namesfield - Ensure that
enable usage as a statistical backgroundis checked at4) set additional options... - Click
CONTINUEto map your IDs. This may take several minutes.
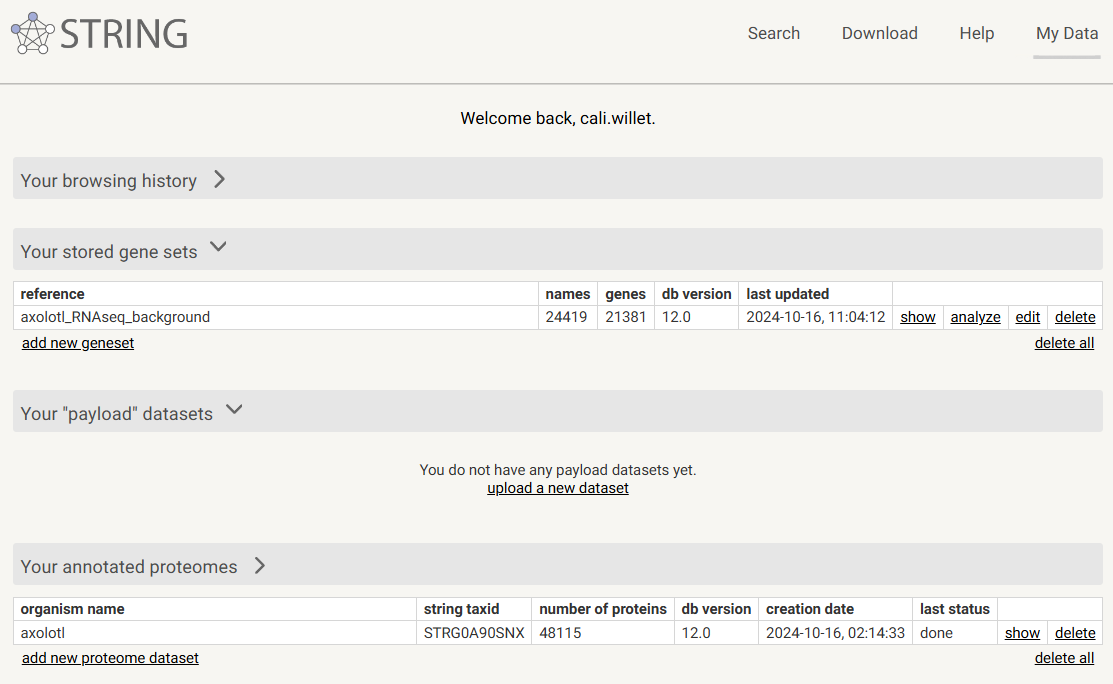
STRING saves your custom datasets under My Data:
Now let’s explore the results!
Some suggestions:
- Select a node on the network, and then
Show this node's terms in the analysis tableto highlight the terms the gene was present in - Select the coloured lines connecting nodes to show evidence suggesting a functional link (all putative of course!)
- Clicking on the
Analysistab will show the enrichment tables with results for GO, STRING, KEGG, Reactome, TISSUES and UniProt - Below the tables, under
Functional enrichment visualizationyou can changeCategoryto alter which database results are plotted
17.6.1 How do the STRING results compare to those we generated in R?
We expect a large difference in the results because of the differing proteome annotation methods - both the annotation tool and the databases that were annotated against.
The eggNOG emapper annotations we used in R rely on orthology-based predictions, employing extensive similarity searches to map genes to their closest evolutionary counterparts across diverse species. This results in a more comprehensive catalog of functional terms, even if they are inferred rather than directly evidenced.
In contrast, STRING’s custom species annotations are based on high-confidence protein-protein interaction networks and empirical data, which can narrow down the set of enriched pathways. We expect species bias to have a considerable effect when attempting to use this platform for novel species.
First of all we see a difference in the number of genes annotated to terms:
| Method | GO | KEGG Pathways | All |
|---|---|---|---|
| emapper | 21,376 | 12,229 | 39,539 |
| STRING | 36,895 | 21,502 | 38,398 |
And a clear lack of overlap in number of enriched GO terms and term IDs between STRING and the R tools:
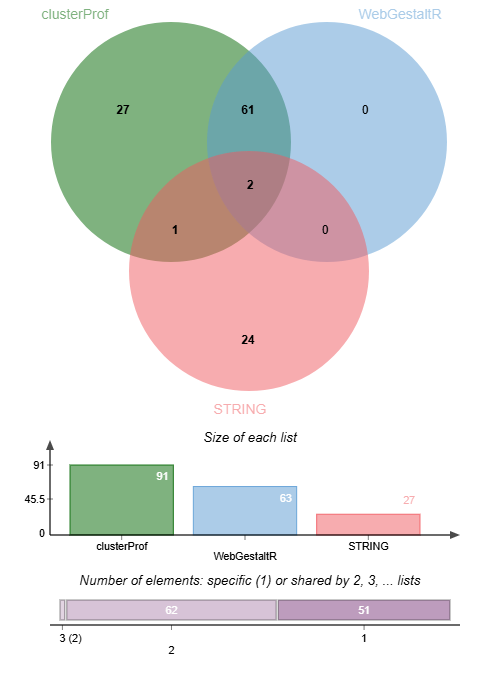
These GO terms from STRING may be parent terms of more specific child terms prevalent in the R output. For a real world analysis, it would be optimal to compare, and deduce whether both methods could provide valuable and complimentary insights, or whether the results from one annotation approach or the other were more suited to your novel species.
Whichever you choose, strength to you! This is not an easy space to work in 💪
Remember the importance of validating your results through other means! 🧪